If we leave aside considerations on the impact of automation across the DevOps life-cycle as we know it, here is what I typically experience (and act on) when introducing, or enhancing, a DevOps model; I RAG-coded each phase to highlight paint points and focus areas:
- KICK-OFF: this is phase zero (the actual Plan phase is discussed at the bottom of this bullet list and relevant to fixes or enhancements as reported by Operations) when I don’t expect major challenges other than intensive work to ensure thorough thinking and strategic decision-making around the preferred development model among those typically considered (TDD, ATDD, BDD, etc), the tools to be adopted by Dev & Ops teams (Rally, Jira, Puppet, etc) and the more-or-less pervasive use of automation.
- CODE: no recurrent issue in this phase other than making sure that the development model previously selected in the Kick-Off phase is applied and monitored with the help of KPIs (two examples of my own are “Sprint-Churn-Rate” and “EAC-Deviation”) to start feeding continuous improvement; focus areas often taken for granted, when possibly they shouldn’t, must contemplate (1) product-architecture knowledge and training across the Development teams, (2) rules and best practices for managing multiple code repositories (especially if dealing with both code trunk and branches) and (3) due diligence/discipline in the recurrent validation of software components (e.g. unit testing, smoke testing, etc).
- BUILD: here is where I normally keep high the level of attention especially when code needs to be maintained in both trunk and branches to respectively keep the off-the-shelf solution up-to-date with recent fixes and enhancements, as well as supporting customers who had requested customization which needs to be retained in future releases; the main risk here is the roll-out of new code into trunk or branches without diligently following rules and best practices and likely to introduce regression destined to haunt us back very soon down the line.
- TEST: this is the first paint point in the cycle as it can impact so much of what follows; here is where attention to detail is key from those who made earlier decisions on the quality assurance model to be adopted; I tend to recommend early-on the ATDD model and follow-suit since it is the one that enables customer-friendly content in terms of test execution and associated pass/fail results, it empowers cross-functional collaboration not just for defining the development user stories with the appropriate level of granularity and it also helps jointly defining and agreeing the acceptance criteria for each story in the test plan.
- RELEASE: not a major pain point, but often the very relevant Release Notes to be packaged with the actual code fall low on the radar and important information such as (1) list of fixes and enhancements, (2) install and integration steps and (3) known issues which have yet to be resolved, all falling on the shoulders of a willing individual (sometimes the Team Lead, others the Developer who did most of the work), which then doesn’t help those on the receiving end experience consistent output in terms of quality; in this scenario I would help setting up best practices and work through roles and responsibilities, starting from the Development Manager who owns consolidation and review of technical information as provided by the developers, but also working together with someone from the Quality Assurance team with the objective of making content consistently laid out release after release as well as customer-friendly.
- DEPLOY: very much dependent on the way the Release phase is executed, but yet carries its own intrinsic challenges; the main one is cross-function (DEV & OPS) synchronization and scheduling of the deployment in the targeted environments whilst taking into account possible temporary constraints such as production freeze periods; if the Release phase suffers from quality issues, then there’ll be a knock-on effect and the Deploy phase will easily escalate to RED status.
- OPERATE: although for some organisations this phase may also contemplate UAT (when for others it is part of Deploy) and it can trigger issues in need of urgent resolution prior go-live, all-in-all it is a business-as-usual kind of scenario, but it is fair to say that this phase will benefit from an early and appropriate issue management approach as well as a qualitative Release phase which clearly tells Operations what they can benefit from in terms of fixes and enhancements and what development work may instead still be required.
- MONITOR: key for this phase is to have in place a well-thought and seamless, effective flow of information by leveraging on the earlier creation of rules, workflows (see an example further below) and after carefully selecting the right tool-set for Operations to use and feed back to Development “intelligence” for improving the solution/s in operation; it is then clear that this phase will benefit from an appropriate due diligence being carried out during the Kick-Off phase when in a collaborative effort the tools to manage development tasks and operational support are selected; a fairly recent experience saw me involved in an organisation using Rally for development purposes and Jira for support; because of this we were experiencing a fragmented flow of ticket-related info (previously logged in Jira) for the Development teams to troubleshoot, categorise, prioritise and plan in future Sprints or the Release Train; although the Development teams were more keen in keeping Rally as their working tool because it was perceived as being better than Jira for their current needs, after leading an internal consultation a collective decision was reached to migrate the Development teams to Jira and therefore benefit from the use of a single tool that would guarantee a more seamless flow of valuable information across development and operational support.
- PLAN: here is the phase when scheduling work on fixes or product enhancements previously submitted by Operations takes place; assuming the tools in use across Operations and Development are already supporting a seamless flow of work packages, the most recurrent challenges are (1) solid prioritisation rules and practices, (2) estimation of effort and (3) capacity management to pull in work (Programme Increments into an ART or User Stories into a Sprint) from the backlog; these three are the focus areas where I end up spending most of my continuous improvement effort, because to get them right it requires several attempts with different techniques as well as some trial & error before being able to appreciate tangible improvements; let’s not forget that by getting right prioritisation, estimation and capacity management, we are manipulating the “key ingredients” of high performance teams.
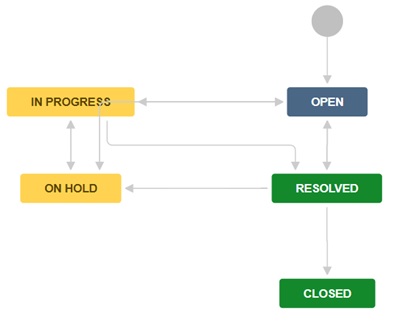
Before ending this post, and to follow-up on a note I wrote in the Monitor phase, I thought of adding a real-life example of workflows configured in Jira which although they very much look-alike, they are not identical; the first one shows the evolution of status from the point of origin of a new issue (request for bug-fixing, or enhancement) as a new ticket logged by Operations/Customer all the way to closed; “In Progress” here means analysis and validation and not just development work, as we still don’t know whether the issue is product-related or else – in the latter case we want to be able to move status straight from “In Progress” to “Closed” after adding in the ticket a comment to explain why no further action from Development is required:
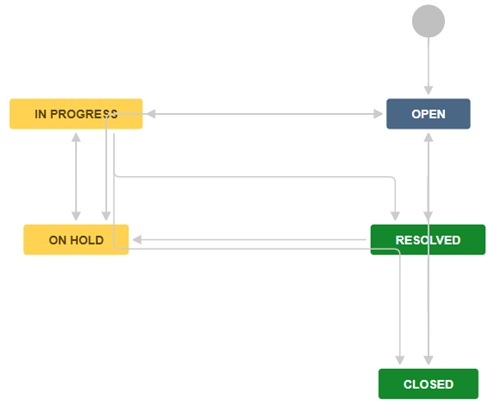
The second workflow here below is specific to the execution of actual bug-fixing work and it should follow the creation of a new user story to be associated to the Jira ticket with breakdown in tasks – you will notice that in this case you can’t move status directly from “In Progress” to “Closed” without going through “Resolved”, and this is because with actual development work having been performed, it is for Operations/Customer to validate the closure of the ticket after very likely carrying out their own UAT: